Detection Engineering Metric Scoring Framework
Goal
As part of my employer's revamp of its current Detection Engineering (DE) program, one of the major tasks for the team was defining a framework of metrics that could be used to score the detection that were produced by the program. These metrics would provide insight into areas about the overall quality of a detection, the amount of coverage for a given MITRE ATT&CK technique, and perhaps most importantly, the progress of the overall DE program itself.
The team’s initial attempt at a framework was heavily influenced by Cyb3rWard0gs (Roberto Rodriguez) How Hot Is Your Hunt Team?, in particular, the section titled “Define Your Scoring System”. I would highly recommend to anyone to take the time to read the article as it is very informative. The idea was to score all of our detections with the framework defined in the article:

As described in the article, this would allow our team to produce a heat map of the ATT&CK matrix which could show the progress of the DE program over time, as well as the relative coverage for a particular technique.
However, it soon became apparent that the above metrics would be insufficient in providing the desired level of insight into our detections. So, our team decided to create our own scoring framework. It would be used not only to score our new detections, but also to rescore ones that have already been produced. What follows it our DE program’s attempt to create a scoring framework that meets the specific requirements of our organization.
Mindset
Before scoring any detections, it was important to ensure that any DE analyst be in the correct mindset. The goal being to produce consistent results across different analysts. Our team came up with some explanations that are meant to prime the analysts way of thinking. The hope is that two or more analysts working independently would come to the same conclusion about the metrics for a detection. Getting into the correct mindset can be difficult, and it can really only be achieved through the repetitious process of scoring alerts, comparing those results with the results of other analysts, peer review, and analysts discussing/defending how they came to their conclusions.
An important thing caveat we wanted to establish was that a detection should be scored based on the detection logic as it is written. It might be tempting to reduce the metric score of a detection in one area or another because there is some problem with the detection. Any problems with the detection should be called out in the Issues section of the ADS page for that detection. The Alerting and Detection Strategy (ADS) is a framework developed by Palantir that we use to describe our detections, and we simply added a section to it to discuss any open issues with a detection. Their article is also a worthwhile read. The point is that the detection should be scored as it is, not as it could be.
Some example that came up early on in our rescoring process:
- There was a detection that alerted on when certain sensitive file extensions where accessed on network file shares. The detection was looking for a particular signature in the logs of one of our security tools. However, the signature hadn’t been seen in our SIEMS’s logs for the tool in the past 90 days. In fact, there wasn’t even a signature field in the logs over the past 90 days either. The question came up of how this would affect the Data Quality score (explained more below). Was the issue with the query logic itself, or the log data? If the former were true, the Data Quality would not be affected, and if the latter were true, it would affect the Data Quality score. In the end, it was decided that the query logic was clearly written to detect that specific signature. This, along with some context from internal documentation about the detection, indicated that the signature must have existed at some point; otherwise, why would the analyst have written the detection in that way? Therefore, the issue lay somewhere in the logs which meant that the Data Quality score had to be lowered since it did not contain the necessary information for the detection to be successful.
- There was a detection whose title implied it was designed to detect the creation or modification of system processes (this matched what was written in the Goal section of the ADS page for that detection). But, the ATT&CK sub-technique it linked to was for the creation and modification of Windows services. Furthermore, the query logic was specifically tailored to detect Windows service creation and modification via sc.exe. The basic issue here is that the stated goal of the detection differs from the activity the query logic was trying to catch. So while evaluating the Data Quality, it was clear that the logs didn’t have enough coverage to comprehensively detect the creation or modification of system processes, much less Windows services, because certain information was missing, like visibility into PowerShell. That begs the question: should the Data Quality score be lower? Ideally the query logic should match the goal. But in this case, the goal was so far off that it was what needed to be changed. The detection needed to be scored as it was written, and so far as the query logic was concerned, the Data Quality was good.
Technique Level Metrics
Very early on in the brainstorming process, it became clear that some of the types of information that we wanted to know were about a detection itself, while others were about the overall technique. Therefore, it made sense to have two “levels” of metrics: one that described the attributes of a detection, and one that described the attributes of a technique. The technique level metrics represent measurable aspects that are unique to one of the techniques in the ATT&CK matrix.
Technique Coverage
Technique Coverage measures the percentage of behaviors encompassing a technique that are able to be detected by existing detections. Our definition for what a behavior is still a work in progress. But it can loosely be defined as a distinct set of actions that a threat actor can take to execute a technique. A detection or test case (made by our Red Team) will often center around one of these behaviors.
The scale for this metric ranges from 0% and 100% (values should be rounded to the nearest whole number). The general formula for this metric can be described as:
The number of behaviors covered by existing detections for a technique / The total number of behaviors for a technique
Usually, the denominator would be equal to the number of test cases developed by the Red Team for a technique. However, there could be cases where it is not feasible to create a test case for a certain behavior. These still need to be taken into account as they represent gaps in our ability to detect a technique. Another important point, whether or not the alert has been validated and the rate at which it caught the test cases should not be taken into account when determining the Technique Coverage. This will be done when calculating the “Magic Number” (discussed more below).
One important consideration when calculating the Technique Coverage is which operating system the detections for that technique applies to. The operating system for a technique can be determined by the value in the Platform field on MITRE’s web page for the technique. Each detection also has an annotation in the SIEM that denotes the Platform and it should match what is on the corresponding technique’s page. If a technique is multi-platform, but all the detections are geared towards Windows, then the lack of coverage for MacOS and Linux needs to be taken into account and the coverage score would be decreased. On the other hand, if the technique applies to only one platform, then coverage on other operating systems is not a concern and the score would be unaffected.
The metric is tracked in a lookup table in our SIEM. The analyst should include a justification for how they decided on the score they chose.
Detection Level
These metrics represent measurable aspects that are unique to a single detection created for a technique in the ATT&CK matrix.
Data Quality
Data Quality measures the overall usefulness, relevance, and verbosity of the contents of the data within the logs being used for the detection. When rescoring detections, it should be noted that the detection should be scored based on how the query logic is written and the sort of activity it is trying to alert on. The scale is as follows:
- Low Quality — The quality of the data is such that it represents the bare minimum need to create a detection detection. The logs do not contain much useful information.
- Good Quality — The quality of the data is enough to create a detection that can stand on its own and effectively alert on the behavior of the technique being targeted. However, the logs don’t contain enough information to create a more advanced, robust detection. Other logging sources might be considered in order to fill in any gaps. Analysts investigating the detection will likely need to supplement the information it gives them with other data sources in order to lead them to a conclusion.
- Exceptional Quality — The data quality means that it is now possible to implement more flexible and sophisticated detections. Other logging sources are likely not necessary as the data contains all necessary information. An analyst investigating the detection has deeper insight into what occurred, allowing them to come to a quick and confident conclusion.
The analyst should add a justification to the Strategy Abstract section of the ADS page for the detection explaining why they chose one score over another. The score itself is stored in an annotation for the detection in our SIEM.
One of the key features of this metric, and our other ones, is its simplicity. Cyb3rWard0g’s basic scoring scale had 6 categories while this one employs 3. This decision was made during attempts at scoring using Cyb3rWard0g’s scale. Our team felt it was too difficult and time consuming to decide, for example, whether or not a detection should be rated as “Fair” or “Good”. It felt like we were splitting hairs, and the difference between them was small enough that we felt it didn’t really mattered in the end. With our scale, it is usually quite clear which one applies to a detection. This means they can be scored quickly and the metric provides a no nonsense answer about the quality of the data the detection is using. This is by no means a critique of Cyb3rWard0g’s scale, as it is what pointed us in the right direction. He even says in his article that, “This is a basic example. I recommend you come up with your own ones,” which is precisely what we did.
Sophistication
Sophistication is a measure of the ability of a detection to flexibly alert on the behavior of a technique as a result of how advanced the analytical logic employed is. It also accounts for how susceptible the detection is to evasion. The scale is as follows:
- Basic — The detection is primarily “signature” based. It looks for a handful of hardcoded values in the logs in order to alert on a specific behavior.
- Intermediate — The detection goes beyond the use of basic signatures, but isn’t quite to the point of making use of more sophisticated analytical features. It alerts on aspects beyond what is seen at the surface level for a technique by looking deeper into the abstraction map (see here for the SpecterOps article explaining Capability Abstraction) and the behaviors it represents. The detection is somewhat effective against evasion efforts.
- Advanced — The detection makes use of highly developed analytics such as machine learning to detect anomalies or sequenced events in the SIEM. The result is the detection remains effective against evasion efforts by an adversary.
The analyst should add a justification to the Technical Context section of the ADS page for the detection explaining why they chose one score over another. The score itself is stored in an annotation for the detection in our SIEM.
Risk Score
Risk score is a value between 0% and 100% that corresponds to how risky an event is. This could also be thought of as the “maliciousness” of an event. This value can accumulate in the SIEM for a user or endpoint to provide insight into potentially malicious activity occurring the might not normally trigger a detection. The value is derived from the formula:
Risk Score= (Impact * Confidence)/100
The value should be rounded to the nearest whole number). The formula was taken from Splunk’s article on How are risk score calculated for RBA. Impact and confidence are also values between 0 and 100. Impact captures the effect the attack will have on an organization, and confidence is how accurate the query logic is at catching said threat. The impact and confidence scores that are used to calculate the risk score should be recorded on the ADS page for the detection in question. A justification should be included with the scores in the “Risk Score Justification” (another custom addition to the ADS framework) of the ADS page. The score itself is stored in an annotation for the detection in our SIEM.
Risk Scoring
- 0–24 — Low Risk/Impact/Confidence.
- 25–49 — Medium Risk/Impact/Confidence.
- 50–74 — High Risk/Impact/Confidence.
- 75–100 — Critical Risk/Impact/Confidence.
The numeric thresholds have been slightly alerted from what Splunk suggested based on internal discussion among the DE team.
Impact
Impact is the measure of the potential impact that the activity the detection is alerting on could have on the organization. A narrow definition of “activity” should be used when thinking about impact. That means the activity being considered is the specific use case of the detection itself. Put another way, only take into account what the detection is explicitly looking for. For example, in a detection looking for odd file extension on the packages being passed to msiexec.exe, the activity would be the presence of packages with those odd file extensions as opposed to the broader activity of the technique itself, in this case, system binary proxy execution with msiexec. There are several other important things to consider when trying to evaluate the impact score of a detection. Any possible “noise”, such as false positives, that could come from the detection should not be taken into account. When thinking about the impact, it is important to assume that any of the activity that occurred was done so with malicious intent. Additionally, mitigating factors, such as having certain security tooling or an Incident Response process, should not be taken into account. In other words, only the “raw” impact should be considered.
- Low Impact — The activity will likely result in very few repercussions to the organization.
- Medium Impact — The activity has the potential to cause damages to the organization.
- High Impact — The activity will likely require further analysis and will likely result in significant damages to the organization.
- Critical Impact — The activity will likely cause catastrophic damage to the organization.
Confidence
Confidence is a measure of how likely it is that the detection will catch the malicious or suspicious activity. Activity should be thought of the same way it was described in the above section on impact. Unlike impact, malicious intent should not be assumed when considering confidence. Another difference between impact and confidence is that confidence is affected by the noise a detection could produce. Things to consider that might lower the confidence score could be the potential for events that are unrelated to the activity being target accidentally getting alerted on or if a detection that alerts on many events, few of which actually constitute malicious or suspicious activity. If it is difficult to ascertain whether or not these events are false positives, then the analyst must use their best judgement. This should be informed by previous attempts to analyze and investigate the search results for false positives during the development phase of the detection. Another thing to consider that could affect the confidence score is the potential for false negatives. For example, a more basic detection (in terms of Sophistication) could be bypassed by various evasion or obfuscation techniques, although there are other ways false negatives could occur. This leads to a false negative (no detection being triggered even though an event did occur) which reduces the confidence that the detection is able to catch malicious or suspicious activity. Even if a detection is looking specifically for attempts at evasion, the potential for further evasion and false negatives must still be considered to the best of the analysts abilities.
- Low Confidence — There will almost certainly be false positives since the detection is broad and/or the likelihood for false negatives is high.
- Medium Confidence —False positives are possible, but the detection has some tuning so overall they are less likely. A reasonable potential for false negatives still exists.
- High Confidence — The rule will catch almost exactly what the author intended it to find with few false positives or negatives.
- Critical Confidence — There is no way to get false positives or negatives. The criteria of the search is very well defined and has been extensively tuned for the environment it is in.
The definitions for each of these criteria still need a little refinement.
Example Table
All values in the table were derived using the maximum value for each category (Low, Medium, High, Critical). They are only examples of what a score could be, and the values in the table do not necessarily have to be used when scoring a detection.
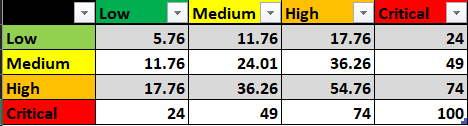
Validation Score
Validation score represents the “report card” for a detection. After a detection is created, it must be validated either manually or using an automated tool. The test case(s) used are the ones initially created by the Red Team to emulate the behavior of the technique and generate logs for the Blue Team to analyze. The scale is a percentage between 0% and 100% (values should be rounded to the nearest whole number). For example, if a detection covers 3 Red Team test cases but is only able to successfully alert on 2 of them, it would get a score of 67%. The score is not tracked in an annotation within the detection itself, but rather the ADS page for the detection and a lookup table within the SIEM. The analyst should include a justification for how they came up with the score in the “Validation Score” section (another custom addition to the ADS framework) of the ADS page for the detection.
The “Magic Number”
The number that answers the fundamental question of “how well our organization able to detect a particular technique?”. This is the number that will populate the heat map of the ATT&CK matric in ATT&CK Navigator. It is made up of the following parts:
- Technique Coverage
- Confidence Score
- Validation Score
Since Confidence Score and Validation Score are at the detection level, their values for all of the detections of a technique will be aggregated into one value.
Note: The value must be taken into context with the metrics generated by the Red Team for their test cases otherwise the number loses some of its meaning. The Red Team metrics should indicate how good the Red Team’s test cases for a technique are (how well they execute them, if they comprehensively cover all the behaviors of a technique).
This metric is, at the moment, the least well defined and has the most ambiguity around it. The two main questions relating to it are which metrics should be used in calculating it, and what exactly is the formula for that calculating it? It was obvious that Technique Coverage was going to be the main metric, but it doesn’t tell the whole story. A technique could be well covered with detections, but if those detections are of poor quality, then those gaps need to be reflected one way or another. That is why, after much discussion, the Confidence Score (which goes into the Risk Score) and Validation Score where chosen for consideration as well. They provide much needed context to the Technique Coverage Score. The two metrics should act as a modifier that influences Technique Coverage in order to arrive at the “Magic Number”. A tentative formula is as follows:
Technique Coverage * ((Risk Score 1 + Risk Score 2 + Risk Score N)/Total Number of Detections for a Technique) * ((Validation Score 1 + Validation Score 2 + Validation Score N)/Total Number of Detections for a Technique)
This formula ultimately has issues in that the Risk and Validation Scores can negatively influence Technique Coverage too much to the point where the resulting “Magic Number” does not paint an accurate picture of our detection capabilities for a technique. As such, it is still a work in progress.
Conclusion
As our organization’s DE program is still young, it was important to make sure that the metrics we created were flexible enough to accommodate future any use cases we hadn’t thought of. It would be a shame to score all of our detections with these metrics only to find some fundamental issue with the framework later on that would cause of to have to rescore everything. The metrics themselves are still being refined as questions arise, and the search for a formula for the “Magic Number” is still very much underway.
We welcome any comments, suggestions (especially in regards to the “Magic Number”, or criticisms that the DE or broader security community have to offer, as things are still very much in progress. We also hope that our framework could be useful to other organizations seeking something similar.